publications
2026
- arxiv
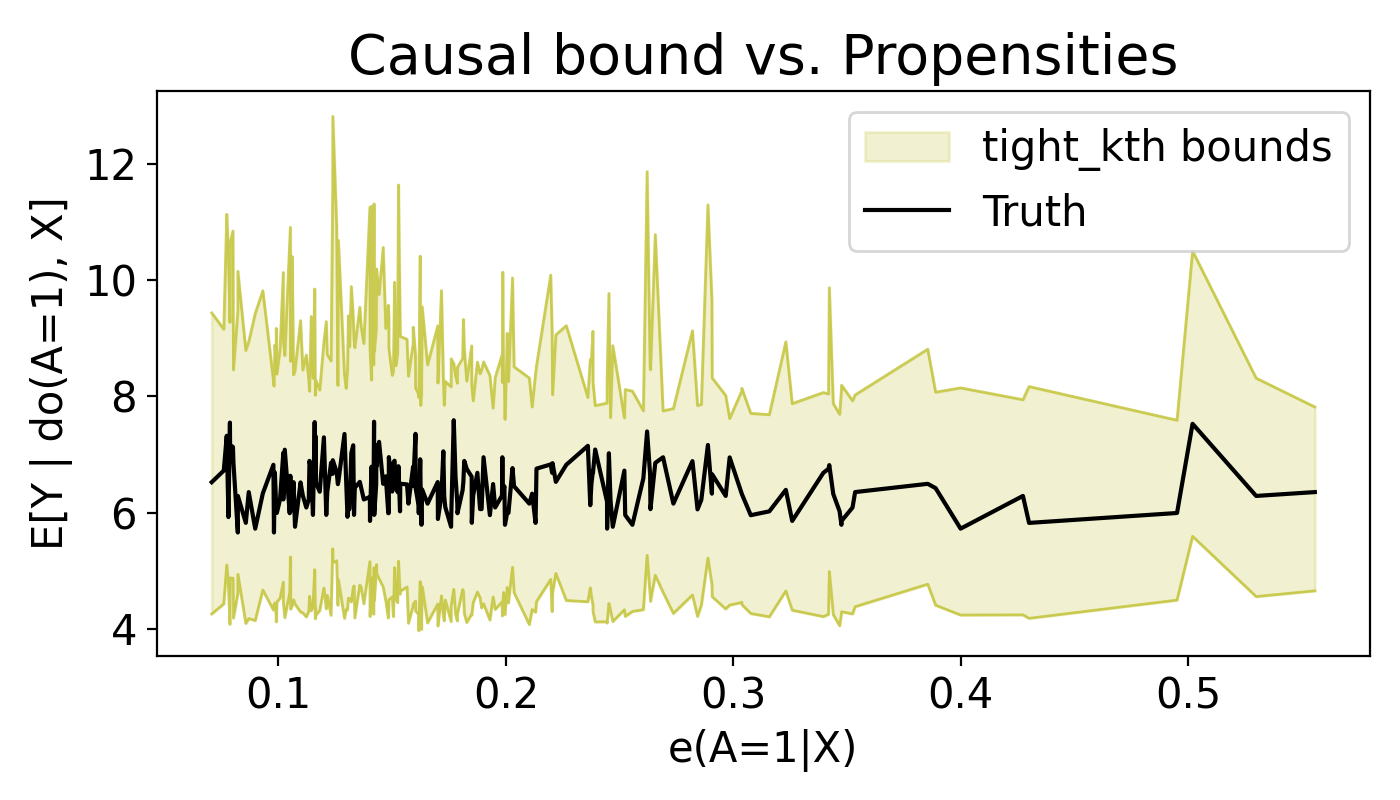 R-19Information-Theoretic Causal Bounds under Unmeasured ConfoundingYonghan Jung and Bogyeong Kang2026partial-identificationheterogeneous-treatment-effect
R-19Information-Theoretic Causal Bounds under Unmeasured ConfoundingYonghan Jung and Bogyeong Kang2026partial-identificationheterogeneous-treatment-effectWe develop a data-driven information-theoretic framework for the sharp partial identification of causal effects under unmeasured confounding. Existing approaches often rely on restrictive assumptions, such as bounded or discrete outcomes, require external inputs (e.g., instrumental variables, proxies, or user-specified sensitivity parameters), necessitate full structural causal model specifications, or focus solely on population-level averages while neglecting covariate-conditional treatment effects. We overcome all four limitations simultaneously by establishing novel information-theoretic, data-driven divergence bounds. Our key theoretical contribution establishes that the f-divergence between the observational distribution P(Y | A=a,X=x) and the interventional distribution P(Y | do(A=a), X=x) is upper bounded by a function of the propensity score alone. This result enables sharp partial identification of conditional causal effects directly from observational data, without requiring external sensitivity parameters, auxiliary variables, full structural specifications, or outcome boundedness assumptions. For practical implementation, we develop a semiparametric estimator satisfying Neyman-orthogonality, which ensures \sqrtn-consistent inference even when nuisance functions are estimated via flexible machine learning methods. Simulation studies and real-world data applications demonstrate that our framework provides tight and valid causal bounds across a wide range of data-generating processes.
@misc{jung2026ITB, title = {Information-Theoretic Causal Bounds under Unmeasured Confounding}, author = {Jung, Yonghan and Kang, Bogyeong}, year = {2026}, eprint = {2601.17160v2}, archiveprefix = {arXiv}, primaryclass = {stat.ML}, keyword1 = {partial-identification}, keyword2 = {heterogeneous-treatment-effect}, rid = {R-19}, } - ICLR
 R-18Debiased Front-Door Learners for Heterogeneous EffectsYonghan JungIn International Conference on Learning Representations (ICLR), 2026front-door-adjustmentheterogeneous-treatment-effect
R-18Debiased Front-Door Learners for Heterogeneous EffectsYonghan JungIn International Conference on Learning Representations (ICLR), 2026front-door-adjustmentheterogeneous-treatment-effectIn observational settings where treatment and outcome share unmeasured confounders but an observed mediator remains unconfounded, the front-door (FD) adjustment identifies causal effects through the mediator. We study the heterogeneous treatment effect (HTE) under FD identification and introduce two debiased learners: FD‑DR‑Learner and FD‑R‑Learner. Both attain fast, quasi-oracle rates (i.e., performance comparable to an oracle that knows the nuisances) even when nuisance functions converge as slowly as n^-1/4. We provide error analyses establishing debiasedness and demonstrate robust empirical performance in synthetic studies and a real-world case study of primary seat-belt laws using Fatality Analysis Reporting System (FARS) dataset. Together, these results indicate that the proposed learners deliver reliable and sample-efficient HTE estimates in FD scenarios. The implementation is available at \urlhttps://github.com/yonghanjung/FD-CATE.
@inproceedings{jung2025fdcate, title = {Debiased Front-Door Learners for Heterogeneous Effects}, author = {Jung, Yonghan}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2026}, eprint = {2509.22531}, archiveprefix = {arXiv}, primaryclass = {stat.ML}, keyword1 = {front-door-adjustment}, keyword2 = {heterogeneous-treatment-effect}, rid = {R-18}, }
2025
- NeurIPS
 R-17Path-specific effects for pulse-oximetry guided decisions in critical careKevin Zhang,Yonghan Jung,Divyat Mahajan,Karthikeyan Shanmugam, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS), 2025healthcaretrustworthyfairness
R-17Path-specific effects for pulse-oximetry guided decisions in critical careKevin Zhang,Yonghan Jung,Divyat Mahajan,Karthikeyan Shanmugam, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS), 2025healthcaretrustworthyfairnessIdentifying and measuring biases associated with sensitive attributes is a crucial consideration in healthcare to prevent treatment disparities. One prominent issue is inaccurate pulse oximeter readings, which tend to overestimate oxygen saturation for dark-skinned patients and misrepresent supplemental oxygen needs. Most existing research has revealed statistical disparities linking device errors to patient outcomes in intensive care units (ICUs) without causal formalization. In contrast, this study causally investigates how racial discrepancies in oximetry measurements affect invasive ventilation in ICU settings. We employ a causal inference-based approach using path-specific effects to isolate the impact of bias by race on clinical decision-making. To estimate these effects, we leverage a doubly robust estimator, propose its self-normalized variant for improved sample efficiency, and provide novel finite-sample guarantees. Our methodology is validated on semi-synthetic data and applied to two large real-world health datasets: MIMIC-IV and eICU. Contrary to prior work, our analysis reveals minimal impact of racial discrepancies on invasive ventilation rates. However, path-specific effects mediated by oxygen saturation disparity are more pronounced on ventilation duration, and the severity differs by dataset. Our work provides a novel and practical pipeline for investigating potential disparities in the ICU and, more crucially, highlights the necessity of causal methods to robustly assess fairness in decision-making.
@inproceedings{zhang2025pathspecificeffectspulseoximetryguided, title = {Path-specific effects for pulse-oximetry guided decisions in critical care}, author = {Zhang, Kevin and Jung, Yonghan and Mahajan, Divyat and Shanmugam, Karthikeyan and Joshi, Shalmali}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {38}, year = {2025}, eprint = {2506.12371}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, keyword1 = {healthcare}, keyword2 = {trustworthy}, keyword3 = {fairness}, rid = {R-17}, } - CVPR
 R-16Sufficient invariant learning for distribution shiftTaero Kim,Subeen Park,Sungjun Lim,Yonghan Jung, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025CRLOOD
R-16Sufficient invariant learning for distribution shiftTaero Kim,Subeen Park,Sungjun Lim,Yonghan Jung, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025CRLOODLearning robust models under distribution shifts between training and test datasets is a fundamental challenge in machine learning. While learning invariant features across environments is a popular approach, it often assumes that these features are fully observed in both training and test sets-a condition frequently violated in practice. When models rely on invariant features absent in the test set, their robustness in new environments can deteriorate. To tackle this problem, we introduce a novel learning principle called the Sufficient Invariant Learning (SIL) framework, which focuses on learning a sufficient subset of invariant features rather than relying on a single feature. After demonstrating the limitation of existing invariant learning methods, we propose a new algorithm, Adaptive Sharpness-aware Group Distributionally Robust Optimization (ASGDRO), to learn diverse invariant features by seeking common flat minima across the environments. We theoretically demonstrate that finding a common flat minima enables robust predictions based on diverse invariant features. Empirical evaluations on multiple datasets, including our new benchmark, confirm ASGDRO’s robustness against distribution shifts, highlighting the limitations of existing methods.
@inproceedings{kim2025sufficient, title = {Sufficient invariant learning for distribution shift}, author = {Kim, Taero and Park, Subeen and Lim, Sungjun and Jung, Yonghan and Muandet, Krikamol and Song, Kyungwoo}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)}, pages = {4958--4967}, year = {2025}, keyword1 = {CRL}, keyword2 = {OOD}, rid = {R-16}, }
2024
- NeurIPS
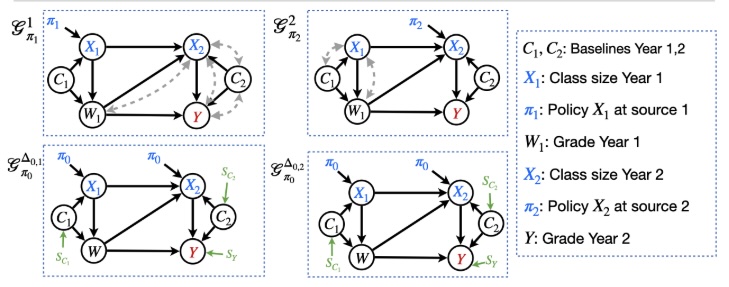 R-15Efficient policy evaluation across multiple different experimental datasetsYonghan Jung and Alexis BellotIn Advances in Neural Information Processing Systems (NeurIPS), 2024estimationfusionOPE
R-15Efficient policy evaluation across multiple different experimental datasetsYonghan Jung and Alexis BellotIn Advances in Neural Information Processing Systems (NeurIPS), 2024estimationfusionOPEArtificial intelligence systems are trained combining various observational and experimental datasets from different source sites, and are increasingly used to reason about the effectiveness of candidate policies. One common assumption in this context is that the data in source and target sites (where the candidate policy is due to be deployed) come from the same distribution. This assumption is often violated in practice, causing challenges for generalization, transportability, or external validity. Despite recent advances for determining the identifiability of the effectiveness of policies in a target domain, there are still challenges for the accurate estimation of effects from finite samples. In this paper, we develop novel graphical criteria and estimators for evaluating the effectiveness of policies (e.g., conditional, stochastic) by combining data from multiple experimental studies. Asymptotic error analysis of our estimators provides fast convergence guarantee. We empirically verified the robustness of estimators through simulations.
@inproceedings{jung2024efficient, title = {Efficient policy evaluation across multiple different experimental datasets}, author = {Jung, Yonghan and Bellot, Alexis}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {37}, pages = {136361--136392}, year = {2024}, keyword1 = {estimation}, keyword2 = {fusion}, keyword3 = {OPE}, rid = {R-15}, } - NeurIPS
 R-14Complete graphical criterion for sequential covariate adjustment in causal inferenceYonghan Jung,Min Woo Park, and Sanghack LeeIn Advances in Neural Information Processing Systems (NeurIPS), 2024ID
R-14Complete graphical criterion for sequential covariate adjustment in causal inferenceYonghan Jung,Min Woo Park, and Sanghack LeeIn Advances in Neural Information Processing Systems (NeurIPS), 2024IDCovariate adjustment, also known as back-door adjustment, is a fundamental tool in causal inference. Although a sound and complete graphical identification criterion, known as adjustment criterion (Shpitser et al., 2010), exists for static contexts, sequential contexts present challenges. Current practices, such as the sequential back-door adjustment (Pearl and Robins, 1995) or multi-outcome sequential backdoor adjustment (Jung et al., 2020), are sound but incomplete; i.e., there are graphical scenarios where the causal effect is expressible via covariate adjustment, yet these criteria do not cover. In this paper, we exemplify this incompleteness and then present the sequential adjustment criterion, a sound and complete criterion for sequential covariate adjustment. We provide a constructive sequential adjustment criterion that identifies a set that satisfies the sequential adjustment criterion if and only if the causal effect can be expressed as a sequential covariate adjustment. Finally, we present an algorithm for identifying a minimal sequential covariate adjustment set, which optimizes efficiency by ensuring that no unnecessary vertices are included.
@inproceedings{jung2024complete, title = {Complete graphical criterion for sequential covariate adjustment in causal inference}, author = {Jung, Yonghan and Park, Min Woo and Lee, Sanghack}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {37}, pages = {19813--19838}, year = {2024}, keyword1 = {ID}, rid = {R-14}, } - NeurIPS
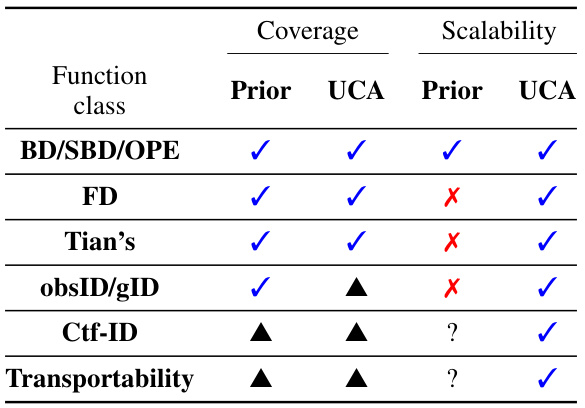 R-13Unified covariate adjustment for causal inferenceYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems (NeurIPS), 2024estimationID
R-13Unified covariate adjustment for causal inferenceYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems (NeurIPS), 2024estimationIDCausal effect identification and estimation are two crucial tasks in causal inference. Although causal effect identification has been theoretically resolved, many existing estimators only address a subset of scenarios, known as the sequential back-door adjustment (SBD) (Pearl and Robins, 1995) or g-formula (Robins, 1986). Recent efforts for developing general-purpose estimators with broader coverage, incorporating the front-door adjustment (FD) (Pearl, 2000) and more, lack scalability due to the high computational cost of summing over high-dimensional variables. In this paper, we introduce a novel approach that achieves broad coverage of causal estimands beyond the SBD, incorporating various sum-product functionals like the FD, while maintaining scalability – estimated in polynomial time relative to the number of variables and samples. Specifically, we present the class of UCA for which a scalable and doubly robust estimator is developed. In particular, we illustrate the expressiveness of UCA for a wide spectrum of causal estimands (e.g., SBD, FD, and more) in causal inference. We then develop an estimator that exhibits computational efficiency and doubly robustness. The scalability and robustness of the proposed framework are verified through simulations.
@inproceedings{jung2024unified, title = {Unified covariate adjustment for causal inference}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {37}, pages = {6448--6499}, year = {2024}, keyword1 = {estimation}, keyword2 = {ID}, rid = {R-13}, }
2023
- tech-report
 R-12A Short Note on Finite Sample Analysis on Double/Debiased Machine LearningYonghan Jung2023estimation
R-12A Short Note on Finite Sample Analysis on Double/Debiased Machine LearningYonghan Jung2023estimationThis note provides learning guarantees for sample-splitting-based estimators, which include double/debiased machine learning (DML) (Chernozhukov et al., 2018) estimators. We prove consistency and Gaussian approximation of estimators using finite-sample arguments, extending the general asymptotic theory. Our work extends previous research (Chernozhukov et al., 2023; Quintas-Martinez, 2022) that studied learning guarantees for the expected linear functional in general sample-splitting-based estimators.
@misc{jung2023short, title = {A Short Note on Finite Sample Analysis on Double/Debiased Machine Learning}, author = {Jung, Yonghan}, year = {2023}, keyword1 = {estimation}, rid = {R-12}, } - NeurIPS
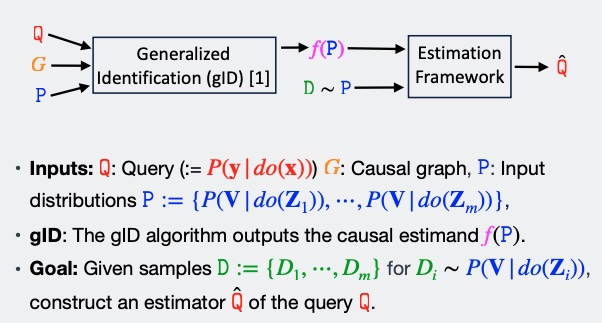 R-11Estimating causal effects identifiable from a combination of observations and experimentsYonghan Jung,Iván Dı́az,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems (NeurIPS), 2023fusionestimationID
R-11Estimating causal effects identifiable from a combination of observations and experimentsYonghan Jung,Iván Dı́az,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems (NeurIPS), 2023fusionestimationIDLearning cause and effect relations is arguably one of the central challenges found throughout the data sciences.Formally, determining whether a collection of observational and interventional distributions can be combined to learn a target causal relation is known as the problem of generalized identification (or g-identification) [Lee et al., 2019]. Although g-identification has been well understood and solved in theory, it turns out to be challenging to apply these results in practice, in particular when considering the estimation of the target distribution from finite samples. In this paper, we develop a new, general estimator that exhibits multiply robustness properties for g-identifiable causal functionals. Specifically, we show that any g-identifiable causal effect can be expressed as a function of generalized multi-outcome sequential back-door adjustments that are amenable to estimation. We then construct a corresponding estimator for the g-identification expression that exhibits robustness properties to bias. We analyze the asymptotic convergence properties of the estimator. Finally, we illustrate the use of the proposed estimator in experimental studies. Simulation results corroborate the theory.
@inproceedings{jung2023estimating, title = {Estimating causal effects identifiable from a combination of observations and experiments}, author = {Jung, Yonghan and D{\'\i}az, Iv{\'a}n and Tian, Jin and Bareinboim, Elias}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {36}, pages = {46446--46490}, year = {2023}, rid = {R-11}, keyword1 = {fusion}, keyword2 = {estimation}, keyword3 = {ID}, } - ICML
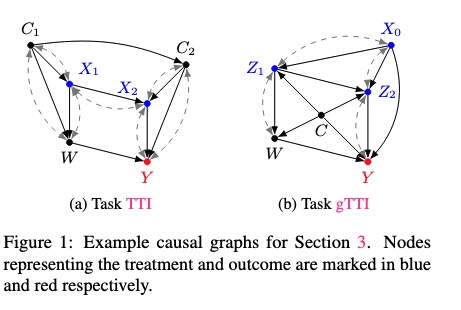 R-10Estimating joint treatment effects by combining multiple experimentsYonghan Jung,Jin Tian, and Elias BareinboimIn International Conference on Machine Learning (ICML), 2023fusionestimationID
R-10Estimating joint treatment effects by combining multiple experimentsYonghan Jung,Jin Tian, and Elias BareinboimIn International Conference on Machine Learning (ICML), 2023fusionestimationIDEstimating the effects of multi-dimensional treatments (i.e., joint treatment effects) is critical in many data-intensive domains, including genetics and drug evaluation. The main challenges for studying the joint treatment effects include the need for large sample sizes to explore different treatment combinations as well as potentially unsafe treatment interactions. In this paper, we develop machinery for estimating joint treatment effects by combining data from multiple experimental datasets. In particular, first, we develop new identification conditions for determining whether a joint treatment effect can be computed in terms of multiple interventional distributions under various scenarios. Further, we develop estimators with statistically appealing properties, including consistency and robustness to model misspecification and slow convergence. Finally, we perform simulation studies, which corroborate the effectiveness of the proposed methods.
@inproceedings{jung2023estimatinh, title = {Estimating joint treatment effects by combining multiple experiments}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {International Conference on Machine Learning (ICML)}, pages = {15451--15527}, year = {2023}, rid = {R-10}, keyword1 = {fusion}, keyword2 = {estimation}, keyword3 = {ID}, }
2022
- ICML
 R-9On measuring causal contributions via do-interventionsYonghan Jung,Shiva Kasiviswanathan,Jin Tian,Dominik Janzing, and 2 more authorsIn International Conference on Machine Learning (ICML), 2022trustworthyestimationID
R-9On measuring causal contributions via do-interventionsYonghan Jung,Shiva Kasiviswanathan,Jin Tian,Dominik Janzing, and 2 more authorsIn International Conference on Machine Learning (ICML), 2022trustworthyestimationIDEstimating the effects of multi-dimensional treatments (i.e., joint treatment effects) is critical in many data-intensive domains, including genetics and drug evaluation. The main challenges for studying the joint treatment effects include the need for large sample sizes to explore different treatment combinations as well as potentially unsafe treatment interactions. In this paper, we develop machinery for estimating joint treatment effects by combining data from multiple experimental datasets. In particular, first, we develop new identification conditions for determining whether a joint treatment effect can be computed in terms of multiple interventional distributions under various scenarios. Further, we develop estimators with statistically appealing properties, including consistency and robustness to model misspecification and slow convergence. Finally, we perform simulation studies, which corroborate the effectiveness of the proposed methods.
@inproceedings{jung2022measuring, title = {On measuring causal contributions via do-interventions}, author = {Jung, Yonghan and Kasiviswanathan, Shiva and Tian, Jin and Janzing, Dominik and Bl{\"o}baum, Patrick and Bareinboim, Elias}, booktitle = {International Conference on Machine Learning (ICML)}, pages = {10476--10501}, year = {2022}, rid = {R-9}, keyword1 = {trustworthy}, keyword2 = {estimation}, keyword3 = {ID}, } - FAccT
 R-8Shortcut Learning in Machine Learning: Challenges, Analysis, SolutionsKyungwoo Song Sanghyuk Chun and Yonghan JungIn ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2022trustworthy
R-8Shortcut Learning in Machine Learning: Challenges, Analysis, SolutionsKyungwoo Song Sanghyuk Chun and Yonghan JungIn ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2022trustworthyRecent advances in deep learning open a new era of practical AI applications. Despite their tremendous successes, numerous case studies have reported that even large-scale ML models with billions of parameters oftentimes fail to generalize in testing environments with heterogeneous data generating processes. For example, if the model was trained to classify the "boat" and "car" from images of [boats in the water] and [cars on the road], the model may wrongly classify new images of [boat on the road] as a "car" by taking the [road] for its decision rules. This phenomenon is called the "shortcut learning bias," which happens when ML models establish their decision rules based on undesired/unintended features [Geirhos et al., 2020], which are correlated but causally irrelevant to outcomes. The shortcut learning bias is a prevalent threat to fairness, accountability, and transparency (FAccT) of ML models because their decision rules may be based on non-causally-related features such as gender or race. In this tutorial, we will outline notions of shortcut learning and discuss methods for alleviating the issue. Specifically, We will exemplify the shortcut learning bias by demonstrating the challenges that modern deep learning models encounter. We will formalize the notion of shortcut learning bias through the lens of causality and invariance. We will review the state-of-the-art techniques for addressing bias. We hope our tutorial will alert the shortcut learning bias risk and encourage developing fair, accountable, and transparent ML methods for experts in the FAccT community.
@inproceedings{jung2022FACCT, title = {Shortcut Learning in Machine Learning: Challenges, Analysis, Solutions}, author = {Sanghyuk Chun, Kyungwoo Song and Jung, Yonghan}, booktitle = {ACM Conference on Fairness, Accountability, and Transparency (FAccT)}, pages = {10476--10501}, year = {2022}, rid = {R-8}, keyword1 = {trustworthy}, }
2021
- NeurIPS
 R-7Double machine learning density estimation for local treatment effects with instrumentsYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems, 2021estimationIV
R-7Double machine learning density estimation for local treatment effects with instrumentsYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in Neural Information Processing Systems, 2021estimationIVabstract=Local treatment effects are a common quantity found throughout the empirical sciences that measure the treatment effect among those who comply with what they are assigned. Most of the literature is focused on estimating the average of such quantity, which is called the local average treatment effect (LATE)” [Imbens and Angrist, 1994]). In this work, we study how to estimate the density of the local treatment effect, which is naturally more informative than its average. Specifically, we develop two families of methods for this task, namely, kernel-smoothing and model-based approaches. The kernel-smoothing-based approach estimates the density through some smooth kernel functions. The model-based approach estimates the density by projecting it onto a finite-dimensional density class. For both approaches, we derive the corresponding double/debiased machine learning-based estimators [Chernozhukov et al., 2018]. We further study the asymptotic convergence rates of the estimators and show that they are robust to the biases in nuisance function estimation. The use of the proposed methods is illustrated through both synthetic and a real dataset called 401(k).
@inproceedings{jung2021double, title = {Double machine learning density estimation for local treatment effects with instruments}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {Advances in Neural Information Processing Systems}, volume = {34}, pages = {21821--21833}, year = {2021}, rid = {R-7}, keyword1 = {estimation}, keyword2 = {IV}, } - ICML
 R-6Estimating identifiable causal effects on markov equivalence class through double machine learningYonghan Jung,Jin Tian, and Elias BareinboimIn International Conference on Machine Learning, 2021estimationIDcausal discovery
R-6Estimating identifiable causal effects on markov equivalence class through double machine learningYonghan Jung,Jin Tian, and Elias BareinboimIn International Conference on Machine Learning, 2021estimationIDcausal discoveryGeneral methods have been developed for estimating causal effects from observational data under causal assumptions encoded in the form of a causal graph. Most of this literature assumes that the underlying causal graph is completely specified. However, only observational data is available in most practical settings, which means that one can learn at most a Markov equivalence class (MEC) of the underlying causal graph. In this paper, we study the problem of causal estimation from a MEC represented by a partial ancestral graph (PAG), which is learnable from observational data. We develop a general estimator for any identifiable causal effects in a PAG. The result fills a gap for an end-to-end solution to causal inference from observational data to effects estimation. Specifically, we develop a complete identification algorithm that derives an influence function for any identifiable causal effects from PAGs. We then construct a double/debiased machine learning (DML) estimator that is robust to model misspecification and biases in nuisance function estimation, permitting the use of modern machine learning techniques. Simulation results corroborate with the theory.
@inproceedings{jung2021estimating, title = {Estimating identifiable causal effects on markov equivalence class through double machine learning}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {International Conference on Machine Learning}, pages = {5168--5179}, year = {2021}, rid = {R-6}, keyword1 = {estimation}, keyword2 = {ID}, keyword3 = {causal discovery}, } - AAAI
 R-5Estimating identifiable causal effects through double machine learningYonghan Jung,Jin Tian, and Elias BareinboimIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021estimationID
R-5Estimating identifiable causal effects through double machine learningYonghan Jung,Jin Tian, and Elias BareinboimIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021estimationIDIdentifying causal effects from observational data is a pervasive challenge found throughout the empirical sciences. Very general methods have been developed to decide the identifiability of a causal quantity from a combination of observational data and causal knowledge about the underlying system. In practice, however, there are still challenges to estimating identifiable causal functionals from finite samples. Recently, a method known as double/debiased machine learning (DML) (Chernozhukov et al. 2018) has been proposed to learn parameters leveraging modern machine learning techniques, which is both robust to model misspecification and bias-reducing. Still, DML has only been used for causal estimation in settings when the back-door condition (also known as conditional ignorability) holds. In this paper, we develop a new, general class of estimators for any identifiable causal functionals that exhibit DML properties, which we name DML-ID. In particular, we introduce a complete identification algorithm that returns an influence function (IF) for any identifiable causal functional. We then construct the DML estimator based on the derived IF. We show that DML-ID estimators hold the key properties of debiasedness and doubly robustness. Simulation results corroborate with the theory.
@inproceedings{jung2021estimatinh, title = {Estimating identifiable causal effects through double machine learning}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, volume = {35}, number = {13}, pages = {12113--12122}, year = {2021}, rid = {R-5}, keyword1 = {estimation}, keyword2 = {ID}, }
{kind=link}
2020
- NeurIPS
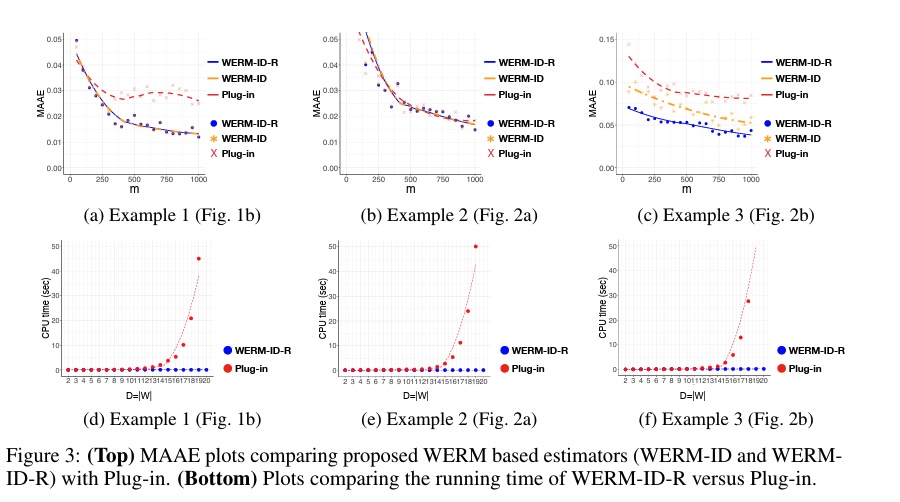 R-4Learning causal effects via weighted empirical risk minimizationYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in neural information processing systems (NeurIPS), 2020estimationID
R-4Learning causal effects via weighted empirical risk minimizationYonghan Jung,Jin Tian, and Elias BareinboimIn Advances in neural information processing systems (NeurIPS), 2020estimationIDLearning causal effects from data is a fundamental problem across the sciences. Determining the identifiability of a target effect from a combination of the observational distribution and the causal graph underlying a phenomenon is well-understood in theory. However, in practice, it remains a challenge to apply the identification theory to estimate the identified causal functionals from finite samples. Although a plethora of effective estimators have been developed under the setting known as the back-door (also called conditional ignorability), there exists still no systematic way of estimating arbitrary causal functionals that are both computationally and statistically attractive. This paper aims to bridge this gap, from causal identification to causal estimation. We note that estimating functionals from limited samples based on the empirical risk minimization (ERM) principle has been pervasive in the machine learning literature, and these methods have been extended to causal inference under the back-door setting. In this paper, we develop a learning framework that marries two families of methods, benefiting from the generality of the causal identification theory and the effectiveness of the estimators produced based on the principle of ERM. Specifically, we develop a sound and complete algorithm that generates causal functionals in the form of weighted distributions that are amenable to the ERM optimization. We then provide a practical procedure for learning causal effects from finite samples and a causal graph. Finally, experimental results support the effectiveness of our approach.
@inproceedings{jung2020learning, title = {Learning causal effects via weighted empirical risk minimization}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {Advances in neural information processing systems (NeurIPS)}, volume = {33}, pages = {12697--12709}, year = {2020}, rid = {R-4}, keyword1 = {estimation}, keyword2 = {ID}, } - AAAI
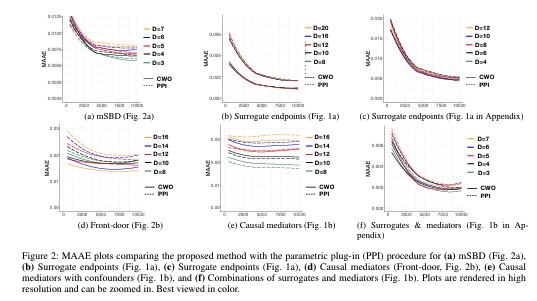 R-3Estimating causal effects using weighting-based estimatorsYonghan Jung,Jin Tian, and Elias BareinboimIn Proceedings of the AAAI Conference on Artificial Intelligence, 2020estimationID
R-3Estimating causal effects using weighting-based estimatorsYonghan Jung,Jin Tian, and Elias BareinboimIn Proceedings of the AAAI Conference on Artificial Intelligence, 2020estimationIDCausal effect identification is one of the most prominent and well-understood problems in causal inference. Despite the generality and power of the results developed so far, there are still challenges in their applicability to practical settings, arguably due to the finitude of the samples. Simply put, there is a gap between causal effect identification and estimation. One popular setting in which sample-efficient estimators from finite samples exist is when the celebrated back-door condition holds. In this paper, we extend weighting-based methods developed for the back-door case to more general settings, and develop novel machinery for estimating causal effects using the weighting-based method as a building block. We derive graphical criteria under which causal effects can be estimated using this new machinery and demonstrate the effectiveness of the proposed method through simulation studies.
@inproceedings{jung2020estimating, title = {Estimating causal effects using weighting-based estimators}, author = {Jung, Yonghan and Tian, Jin and Bareinboim, Elias}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {34}, number = {06}, pages = {10186--10193}, year = {2020}, rid = {R-3}, keyword1 = {estimation}, keyword2 = {ID}, }
2018
- Physiol. measure.
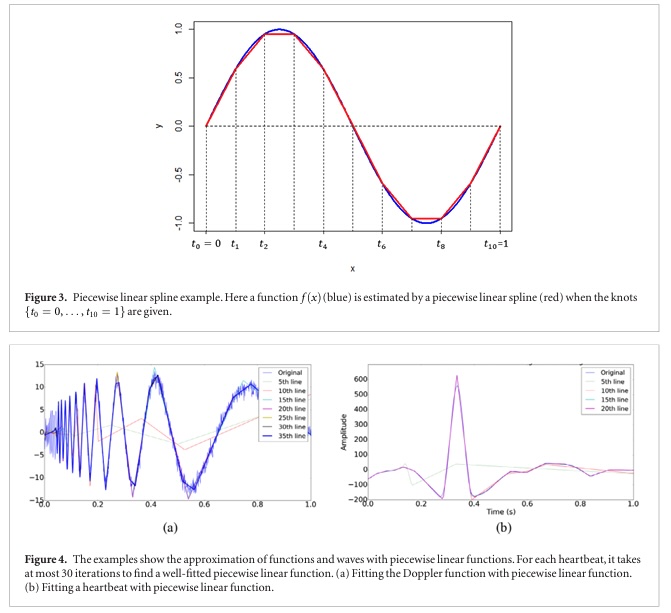 R-2Classification of short single-lead electrocardiograms (ECGs) for atrial fibrillation detection using piecewise linear spline and XGBoostYao Chen,Xiao Wang,Yonghan Jung,Vida Abedi, and 3 more authorsPhysiological measurement, 2018healthcare
R-2Classification of short single-lead electrocardiograms (ECGs) for atrial fibrillation detection using piecewise linear spline and XGBoostYao Chen,Xiao Wang,Yonghan Jung,Vida Abedi, and 3 more authorsPhysiological measurement, 2018healthcareObjective: Detection of atrial fibrillation is important for risk stratification of stroke. We developed a novel methodology to classify electrocardiograms (ECGs) to normal, atrial fibrillation and other cardiac dysrhythmias as defined by the PhysioNet Challenge 2017. Approach: More specifically, we used piecewise linear splines for the feature selection and a gradient boosting algorithm for the classifier. In the algorithm, the ECG waveform is fitted by a piecewise linear spline, and morphological features relating to the piecewise linear spline coefficients are extracted. XGBoost is used to classify the morphological coefficients and heart rate variability features. Main results: The performance of the algorithm was evaluated by the PhysioNet Challenge database (3658 ECGs classified by experts). Our algorithm achieved an average F1 score of 81% for a 10-fold cross-validation and also achieved 81% for F1 score on the independent testing set. This score is similar to the top 9th score (81%) in the official phase of the PhysioNet Challenge 2017. Significance: Our algorithm presents a good performance on multi-label short ECG classification with selected morphological features.
@article{chen2018classification, title = {Classification of short single-lead electrocardiograms (ECGs) for atrial fibrillation detection using piecewise linear spline and XGBoost}, author = {Chen, Yao and Wang, Xiao and Jung, Yonghan and Abedi, Vida and Zand, Ramin and Bikak, Marvi and Adibuzzaman, Mohammad}, journal = {Physiological measurement}, volume = {39}, number = {10}, pages = {104006}, year = {2018}, publisher = {IOP Publishing}, keyword1 = {healthcare}, rid = {R-2}, }
2017
- R-1Detection of PVC by using a wavelet-based statistical ECG monitoring procedureYonghan Jung and Heeyoung KimBiomedical Signal Processing and Control, 2017healthcare
@article{jung2017detection, title = {Detection of PVC by using a wavelet-based statistical ECG monitoring procedure}, author = {Jung, Yonghan and Kim, Heeyoung}, journal = {Biomedical Signal Processing and Control}, volume = {36}, pages = {176--182}, year = {2017}, publisher = {Elsevier}, rid = {R-1}, keyword1 = {healthcare}, }